go 函数方法接口
原文地址:https://www.douyacun.com/article/0f451f0e03545eef38b837d110d69797
疑问:
- 为什么append要返回一个切片?
var a = make([]int, 1, 2)
fmt.Printf("%v\t\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
a = append(a, 2)
fmt.Printf("%v\t\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
a = append(a, 3, 4, 5)
fmt.Printf("%v\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
// [0] &{824634327040 1 2}
// [0 2] &{824634327040 2 2}
// [0 2 3 4 5] &{824634368000 5 6}
-
如果切片容量不足的话,go扩容切片需要重新申请内存,内存地址会发生变化
-
如果切片容量充足,go不需要扩容,底层数组data内存地址也不会发生变化,
func append(slice []Type, elems ...Type) []Type传入的切片也是复制(切片数据结构), 函数的参数是传值, 底层数组部分是通过隐式指针传递(指针本身依然是传值的,但是指针指向的却是同一份的数据),所以被调用函数是可以通过指针修改掉调用参数切片中的数据。除了数据之外,切片结构还包含了切片长度和切片容量信息,这2个信息也是传值的。如果被调用函数中修改了Len或Cap信息的话,就无法反映到调用参数的切片中,这时候一般会通过返回修改后的切片来更新之前的切片。
- 这里注意一下切片a的容量是6,按照我们之前的说法,newcap > 2倍容量时, 取newcap为最终容量,但这里5 > 2 * 2,为什么这里是6呢?内存对齐,最后会解释一下这里的原因
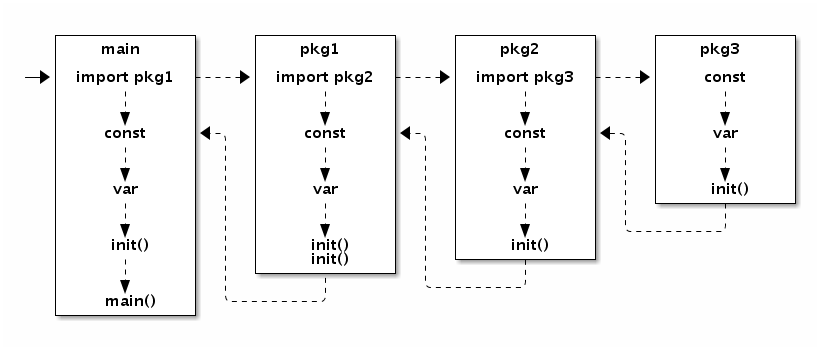
Go语言程序的初始化
执行从main.main开始,如果main导入了其他的包,会按照顺序将他们包含进mian包里
- 如果某个包被多次导入的话,只会导入的时候只会执行一次
- 当一个包被导入的时候如果还导入了其他的包,则会将其他的包先导入进来,创建和初始化常量和变量,再调用包里的init函数
- 如果一个包里的有多个init函数,调用顺序未定义,同一个文件内的init函数则是以顺序依次调用
- 最后,当main包的所有包级变量、常量创建初始化完成,init函数执行之后才会进入main.main
函数
// 具名函数
func Add(a, b int) int {
return a+b
}
// 匿名函数
var Add = func(a, b int) int {
return a+b
}
func Inc() (v int) {
// 闭包,什么是闭包
defer func() {v++}()
return 42
}
// 43,这里为什么是43而不是42
func main() {
for i := 0; i < 3; i++ {
defer func(){ println(i) } ()
}
}
// Output:
// 3
// 3
// 3
- 函数有具名函数和匿名函数之分,包级一般都是具名函数,具名函数是匿名函数的一种特例。
- 当匿名函数引用了外部作用域中的变量时就成了闭包函数,闭包函数是函数式编程语言的核心。
- 函数可以有多个参数和返回值,参数和返回值都是以传值的方式和被调用者交换数据,支持可变参数传值,可变参数必须是最后一个参数,可变数量的参数其实是一个切片类型的参数。
- 函数不仅参数可以有名字,也可以给返回值命名。
- 闭包函数对外部捕获的变量不是以传值方式而是以引用方式传参
- 不建议for循环内部使用defer语句
- 任何可以通过函数参数修改调用参数的情形,是因为函数参数中显式或隐式的传入指针参数
方法
// 关闭文件
func (f *File) Close() error {
// ...
}
// 读文件数据
func (f *File) Read(offset int64, data []byte) int {
// ...
}
- Go语言中,将第一个函数参数移动到函数前面 - 方法
- Go语言中,通过在结构体内置匿名的成员来实现继承
- Go语言中,方法是编译时静态绑定的
接口
Go语言在提供严格的类型检查的同时,通过接口类型实现了对鸭子类型的支持,使得安全动态的编程变得相对容易。
鸭子类型 - 当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。
在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。例如,在不使用鸭子类型的语言中,我们可以编写一个函数,它接受一个类型为"鸭子"的对象,并调用它的"走"和"叫"方法。在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的"走"和"叫"方法。如果这些需要被调用的方法不存在,那么将引发一个运行时错误。任何拥有这样的正确的"走"和"叫"方法的对象都可被函数接受的这种行为引出了以上表述,这种决定类型的方式因此得名。- 维基百科
在Go语言中,对于基础类型(非接口类型)不支持隐式转换,无法将一个int类型的值直接赋值给int64类型的变量,也无法将int的值赋值给底层是int类型新定义命名类型的变量,go语言对类型的一致性要求非常严格,但是对接口转化则是非常的灵活,对象和接口之间的转换、接口和接口之间的转换都可能是隐式的转换。
有时候对象和接口之间太灵活了,导致我们需要人为地限制这种无意之间的适配。常见的做法是定义一个含特殊方法来区分接口。比如runtime包中的Error接口就定义了一个特有的RuntimeError方法,用于避免其它类型无意中适配了该接口:
type runtime.Error interface {
error
// RuntimeError is a no-op function but
// serves to distinguish types that are run time
// errors from ordinary errors: a type is a
// run time error if it has a RuntimeError method.
RuntimeError()
}
type testing.TB interface {
Error(args ...interface{})
Errorf(format string, args ...interface{})
...
// A private method to prevent users implementing the
// interface and so future additions to it will not
// violate Go 1 compatibility.
private()
}
扩容和内存对齐
// 这个例子 讲讲扩容或内存
var a = make([]int, 1, 1)
fmt.Printf("%v\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
a = append(a, 2, 3, 4, 5)
fmt.Printf("%v\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
// [0] &{824634335232 1 1}
// [0 2 3 4 5] &{824634368000 5 6}
按照扩容的第二条,大于两倍旧容量,按理说应该是5但这里是6,那就是接下来的内存对齐了
- capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
- newcap 我们计算出来是5, uintptr(newcap) * sys.PtrSize -> 5 * 8 = 40; roundupsize(40)
- (size+smallSizeDiv-1)/smallSizeDiv] -> (40 + 8 - 1)/8 = 5(这里是因为int存储的,后面小数都是截取)class_to_size[size_to_class8[5]] -> 48
- 48 / 8 = 6 所以最终cap为6