go 类型定义,内存布局,底层数据结构,切片扩容规则
原文地址:https://www.douyacun.com/article/5d64340ba6d00142e41c767d7faf7bf2
疑惑
- 如何区分变量是数组还是切片
- 数组复制是否像c语言一样,只复制数组开始的地址
- 为什么字符串("hello world")计算大小unsafe.Sizeof()是16
数组
定义方式:
var a [3]int // 定义长度为3的int型数组, 数组中的每个元素都以零值初始化
var b = [...]int{1, 2, 3} // 定义长度为3的int型数组, 长度根据初始化元素的数目自动计算
var c = [...]int{2: 3, 1: 2} // 定义长度为3的int型数组, 索引的方式来初始化数组的元素
var d = [...]int{1, 2, 4: 5, 6} // 定义长度为6的int型数组, 元素为 1, 2, 0, 0, 5, 6
概念: 数组是一个固定长度的特定类型元素组成的序列,长度/类型
-
不同长度和类型数据组成数组类型是不同的
-
不同长度的数组因为长度不同无法直接赋值
-
不同于切片,数组的长度是明确指定的
-
不同于c语言数组,go语言数组是值语义,并不是隐式指向第一个元素指针,当一个数组被复制和传递是,实际会复制整个数组
-
len 和 cap 返回的结果始终是对应数组的长度
-
数组可以用于数值、字符串、结构体、函数、接口、管道数组
内存结构:在内存中连续存储
| 1 | 2 | 3 | 4 | 5 |
var a = [...]int{1, 2, 3, 4, 5}
fmt.Println(unsafe.Sizeof(a))
// 40
Sizeof(a)大小是40,我这系统是64位的所以int位64位,8个字节, 8*5 = 40
字符串
概念: 一个字符串是一个不可改变的字节序列
- 字符串是一个只读的字节数组,长度是固定的
- 字符串长度并不是字符串类型的一部分,不同长度的字符串可以等值比较
- 字符串是一个结构体,因此字符串赋值操作也就是reflect.StringHeader复制操作,不会涉及到底层数组的复制
- 字符串是只读的,相同字符串常量,通常是对应同一个字符串常量
- 字符串和数组类似也可以通过len获取字符串长度,StringHeader也可以获取
var a = "Hello world"
fmt.Println(len(a))
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&a)).Len)、
fmt.Println(unsafe.Sizeof(a))
// 11
// 11
// 16
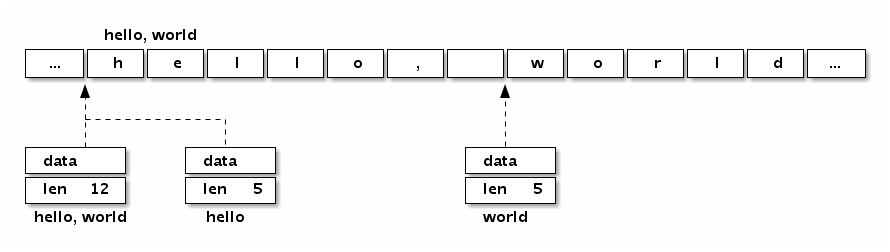
a内存的数据,使用reflect.StringHeader类型来解释,类型强制转换, unsafe.Sizeof(a)其实计算的是,下面reflect.StringHeader结构的大小,unitptr 8字节 + int 8字节 = 16字节,因此可以称呼go字符串为字符串结构体
数据结构在reflect.StringHeader定义:
type StringHeader struct {
Data uintptr
Len int
}
字符串的内存结构:
切片
概念:切片就是一种简化版的动态数组,动态数组的长度不固定,切片相对于数组更具有灵活性#
- 切片的长度不是类型的组成部分,数组的长度需要计算得出
- 容量必须大于或等于切片的长度
- 在对切片本身赋值或参数传递时,和数组指针的操作方式类似,只是复制切片头信息(
reflect.SliceHeader)
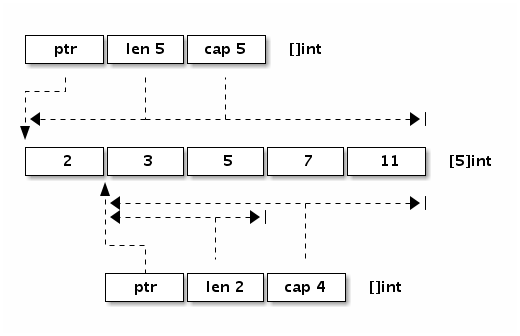
结构体定义:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
内存布局:x := []int{2,3,5,7,11}
切片声明:
var a []int // 这里只是声明类型,结构体还没有初始化,所以为nil
b := []int{} // 结构体已经初始化了
fmt.Println(a == nil, b == nil)
fmt.Println(unsafe.Sizeof(a))// 8 + 8 + 8 = 24
// true false
// 24
g := make([]int, 3) // 有3个元素的切片, len和cap都为3
切片新增和删除:
增加元素:
var a = []int{1, 2, 3, 4}
fmt.Println(a, len(a), cap(a))
// [1 2 3 4] 4 4
a = append(a, 5)
fmt.Println(a, len(a), cap(a))
// [1 2 3 4 5] 5 8
var b = make([]int, 0, 1)
b = append(b, 1, 2, 3, 4, 5, 6)
fmt.Println(b, len(b), cap(b))
// [1 2 3 4 5 6] 6 6
var c = make([]int, 1023, 1024)
c = append(c, 1, 3)
fmt.Println(c, len(c), cap(c))
// [0 0 0 0 ...] 1025 1280
扩容:
在容量不足的情况下,append的操作会导致重新分配内存,可能导致巨大的内存分配和复制数据代价,目的是为了减少向操作malloc申请堆内存的次数,重复的申请代价也是昂贵的
- 期望容量大于当前容量的2倍,使用期望容量
- 当前容量小于1024会将容量翻倍
- 当前容量大于1024,每次增加25%直到大于期望容量
// runtime/slice.go/func growslice(et *_type, old slice, cap int) slice {}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
// uintptr: 能存储指针的整型,也能存储int,官方解释:uintptr is an integer type that is large enough to hold the bit pattern of any pointer.
// sys.PtrSize 64位系统是8
// 内存对齐
// Returns size of the memory block that mallocgc will allocate if you ask for the size.
func roundupsize(size uintptr) uintptr {
// _MaxSmallSize: 32768
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
} else {
return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
}
}
if size+_PageSize < size {
return size
}
return round(size, _PageSize)
}
// size_to_class8: 0, 1, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9......
// class_to_size: 0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160......
扩容和内存对齐
// 这个例子 讲讲扩容或内存
var a = make([]int, 1, 1)
fmt.Printf("%v\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
a = append(a, 2, 3, 4, 5)
fmt.Printf("%v\t%v\n", a, (*reflect.SliceHeader)(unsafe.Pointer(&a)))
// [0] &{824634335232 1 1}
// [0 2 3 4 5] &{824634368000 5 6}
按照扩容的第二条,大于两倍旧容量,按理说应该是5但这里是6,那就是接下来的内存对齐了 capmem = roundupsize(uintptr(newcap) * sys.PtrSize) newcap 我们计算出来是5, uintptr(newcap) * sys.PtrSize -> 5 * 8 = 40; roundupsize(40) (size+smallSizeDiv-1)/smallSizeDiv] -> (40 + 8 - 1)/8 = 5(这里是因为int存储的,后面小数都是截取)class_to_size[size_to_class8[5]] -> 48 48 / 8 = 6 所以最终cap为6
删除元素
a = []int{1, 2, 3}
a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素
a = append(a[:0], a[1:]...) // 删除开头1个元素
a = a[:copy(a, a[1:])] // 删除开头1个元素
a = append(a[:i], a[i+1:]...) // 删除中间1个元素
切片使用技巧
0长切片特性(长度为0,容量不为0),应用场景:过滤掉字符串中的某些字符, 切片高效操作的要点是要降低内存分配的次数
func Filter(s []byte, f func(x byte) bool) []byte {
b := s[:0] // 这里b的长度是0,容量是s容量等价于 var b = make([]byte, 0, cap(s))
for _, x := range s {
if !f(x) {
b = append(b, x)
}
}
return b
}
切片避免内存泄漏, FindPhoneNumber会加载整个文件到内存中,搜索第一个出现的号码,最终结构以切片方式返回,返回结果指向保存整个文件的数组,因为切片引用了整个原始数组,导致垃圾回收器不能及时释放底层的空间
func FindPhoneNumber(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return regexp.MustCompile("[0-9]+").Find(b)
}
类似的问题,在删除切片元素时可能会遇到。假设切片里存放的是指针对象,那么下面删除末尾的元素后,被删除的元素依然被切片底层数组引用,从而导致不能及时被自动垃圾回收器回收
var a []*int{ ... }
a = a[:len(a)-1] // 被删除的最后一个元素依然被引用, 可能导致GC操作被阻碍
var a []*int{ ... }
a[len(a)-1] = nil // GC回收最后一个元素内存
a = a[:len(a)-1] // 从切片删除最后一个元素