当前专题
2026-03-29
5分钟
墩墩
在线体验地址:https://www.douyacun.com/pdf/remove-watermark
PDF 去除文字水印看起来像是在“删字”,真正难的是两件事要同时成立: 先把真正的水印识别出来,再把它精准删除,而且不能误伤正文、标题和页眉。
这篇文章只讲 4 件事: 为什么文字水印更难、早期为什么会误删标题、现在怎么做到更精准、以及怎么优化手动判断水印的操作。
图片水印通常是独立图片对象,定位后就能单独处理。文字水印往往藏在 PDF 内容流里,以 Tj、TJ 这类文字指令存在,程序真正面对的是字体、矩阵、透明度、颜色和所在 stream。
难点主要有 4 个:
ToUnicode/CMap 才能解码。所以,文字去水印本质上不是“删字”,而是“识别 + 判断 + 精准改写 PDF 对象”。
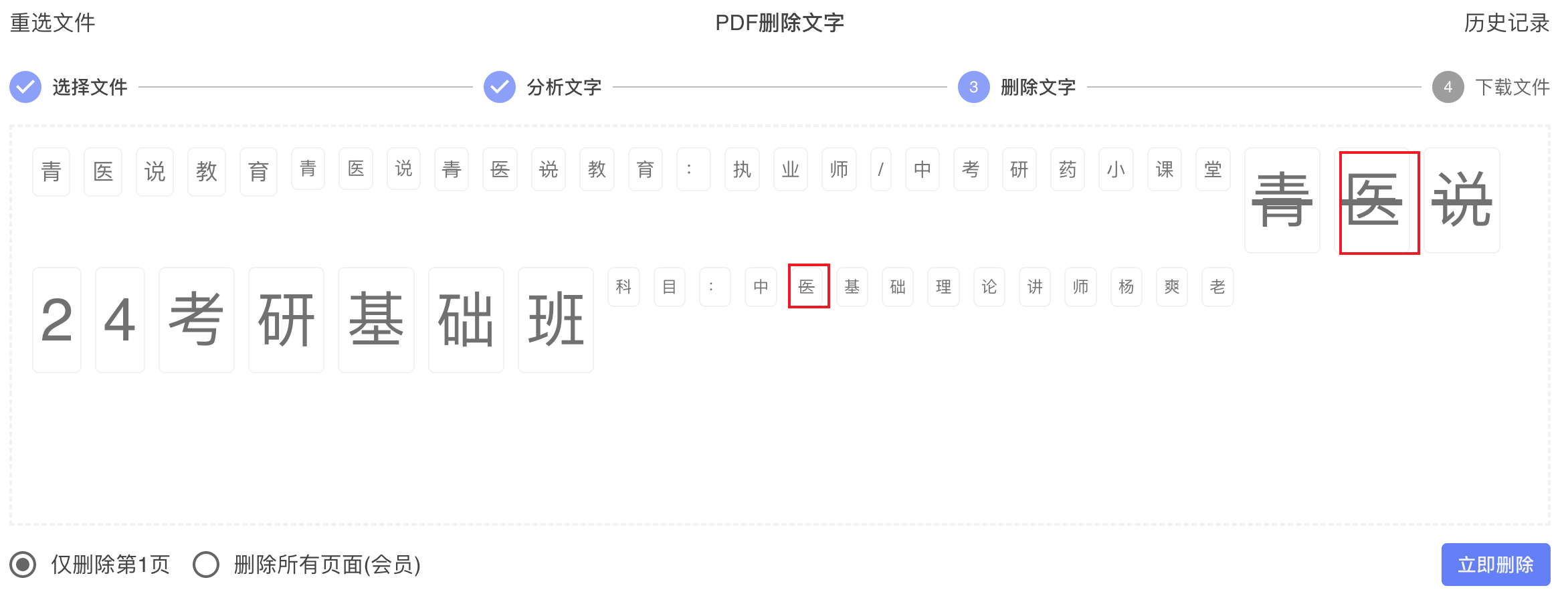
最典型的案例就是“青衣说”。页面里斜着有一层淡色的“青衣说”文字水印,同时正文或标题里还有更大的“青衣说”文字。能看出来哪个是水印,程序如果删除粒度太粗,就可能一起删掉。

早期方案很直接:
raw_textraw_text 拼起来这个方案能快速打通闭环,但问题很明显:
所以,真正要把效果做稳,不能只改删除阶段,识别、展示和交互都得一起优化。
文字识别后来的优化可以概括成 4 步:
Tj、TJ 文字操作,而不是只看页面上能不能读出文字。ToUnicode/CMap 解码十六进制操作数,让候选尽量展示成真实中文,而不是乱码。最终,明显像水印的候选会默认勾选,不确定候选也会返回,但不会默认删除。
识别阶段解决的是“删谁”,删除阶段解决的是“怎么删才不会误伤”。这次最关键的升级,就是把删除从“全局替换字节”改成“语法级精准删除”。
旧方案的问题是: 它只知道某一段字节命中了,不知道这段字节来自哪个 stream_xref、哪一条 Tj/TJ 操作,也不知道字体、矩阵和透明度。结果就是,只要别处也有相似片段,就有误删风险。
新方案的思路是“删除操作,而不是删除字节”。检测阶段会记录 page_no、stream_xref、operator、op_index、matrix、font_xref 等定位信息;删除阶段再重新解析目标 stream,只改写被选中的那一条文字操作。
这里有一个很关键的安全边界: 严禁跨 stream_xref 做 fallback 匹配。
这就是为什么现在选中了水印“青衣说”,不会再顺手把标题里的“青衣说”一起删掉。
后端识别和删除逻辑做对了,只解决了一半问题。如果前端候选展示得不清楚、选择成本太高,一样会觉得这个功能“不好用”。
这次前端主要做了几件事:
这轮优化主要有 3 个变化:
下面这张图展示的是去水印后的结果预览。

真正提升的是候选更容易看懂、选择更高效、删除结果更可信。
当前方案最适合的是这类 PDF:
Tj/TJ 操作表达下面这些情况,仍然建议人工确认:
如果所谓“文字水印”其实已经被烘焙进图片里,比如扫描件上的浅色字样,那它本质上就不再是文字对象水印,而是图片域问题。
PDF 去除文字水印,真正难的不是“能不能删掉几个字”,而是能不能既识别准确,又删除精准,操作起来足够省力。
这次效果提升,核心就来自 5 件事一起成立: 正确解码文字、提取视觉特征、建立候选打分、升级为语法级精准删除,以及优化手动判断和批量选择的操作。
如果你只是想快速使用,也可以直接打开在线页面体验:
https://www.douyacun.com/pdf/remove-watermark